Building a crawler in PHP original
When Spatie unleashes a new site on the web we want to make sure that all, both internal and external, links on it work. To facilitate that process we released a tool to check the statuscode of every link on a given website. It can easily be installed via composer:
composer global require spatie/http-status-check
Let's for example scan the Laracasts.com-domain:
http-status-check scan
Our little tool will spit out the status code of all links it finds:
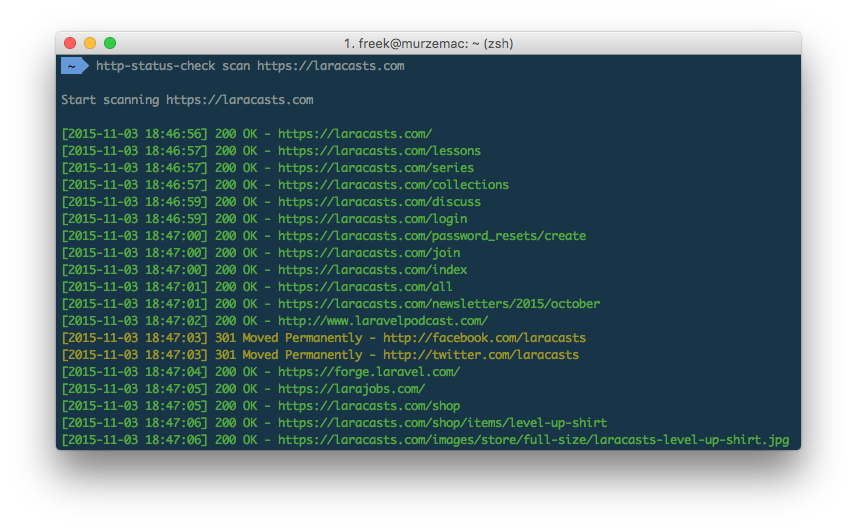
And once finished a summary with the amount of links per status code will be displayed.
The package uses a home grown crawler. Sure, there are already many other crawlers available. I built a custom one part as a learning exercise, part because the other crawlers didn't to exactly what I wanted to.
Let's take a look at the code that crawls all links on a piece of html:
/**
* Crawl all links in the given html.
*
* @param string $html
*/
protected function crawlAllLinks($html)
{
$allLinks = $this->getAllLinks($html);
collect($allLinks)
->filter(function (Url $url) {
return !$url->isEmailUrl();
})
->map(function (Url $url) {
return $this->normalizeUrl($url);
})
->filter(function (Url $url) {
return $this->crawlProfile->shouldCrawl($url);
})
->each(function (Url $url) {
$this->crawlUrl($url);
});
}
So first we get all links. Then we'll filter out mailto-links. The next step normalizes all links. After that we'll let a crawlProfile determine if that link should be crawled. And finally the link will get crawled.
Determining all links on a page
Determining which links there are on a page may sound quite daunting but Symfony's DomCrawler makes that very easy. Here's the code:
protected function getAllLinks($html)
{
$domCrawler = new DomCrawler($html);
return collect($domCrawler->filterXpath('//a')
->extract(['href']))
->map(function ($url) {
return Url::create($url);
});
}
The DomCrawler returns strings. Those strings get mapped to Url-objects to make it easy to work with them.
Normalizing links
On a webpage protocol independent-links (eg. //domain.com/contactpage) and relative links (/contactpage) may appear. To make our little crawler needs absolute links (https://domain.com/contactpage) so all links need to be normalized. The code to do that:
protected function normalizeUrl(Url $url)
{
if ($url->isRelative()) {
$url->setScheme($this->baseUrl->scheme)
->setHost($this->baseUrl->host);
}
if ($url->isProtocolIndependent()) {
$url->setScheme($this->baseUrl->scheme);
}
return $url->removeFragment();
}
$baseUrl in the code above contains the url of the site we're scanning.
Determining if a url should be crawled
The crawler delegates the question if a url should be crawled to a dedicated class that implements the CrawlProfile-interface
namespace Spatie\Crawler;
interface CrawlProfile
{
/**
* Determine if the given url should be crawled.
*
* @param \Spatie\Crawler\Url $url
*
* @return bool
*/
public function shouldCrawl(Url $url);
}
The package provides an implementation that will crawl all url's. If you want to filter out some url's there's no need to change the code of the crawler. Just create your own CrawlProfile-implementation.
Crawling an url
Guzzle makes fetching the html of an url very simple.
$response = $this->client->request('GET', (string) $url);
$this->crawlAllLinks($response->getBody()->getContents());
There's a little bit more to it, but the code above is the essential part.
Observering the crawl process
Again, you shouldn't touch the code of the crawler itself to add behaviour to it. When instantiating the crawler it expects that you pass it a implementation of CrawlObserver
Looking at the interface should make things clear:
namespace Spatie\Crawler;
interface CrawlObserver
{
/**
* Called when the crawler will crawl the url.
*
* @param \Spatie\Crawler\Url $url
*/
public function willCrawl(Url $url);
/**
* Called when the crawler has crawled the given url.
*
* @param \Spatie\Crawler\Url $url
* @param \Psr\Http\Message\ResponseInterface|null $response
*/
public function hasBeenCrawled(Url $url, $response);
/**
* Called when the crawl has ended.
*/
public function finishedCrawling();
}
The http-status-check tool uses this implementation to display all found links to the console.
In closing
That concludes the little tour of the code. I hope you've seen that creating a crawler is not that difficult. If you want to know more, just read the code of the Crawler-class on GitHub.
My colleague Sebastian had a great idea to create a Laravel-package that provides an Artisan command to check all links of a Laravel application. You might seeing that appear amongst our current Laravel packages soon.